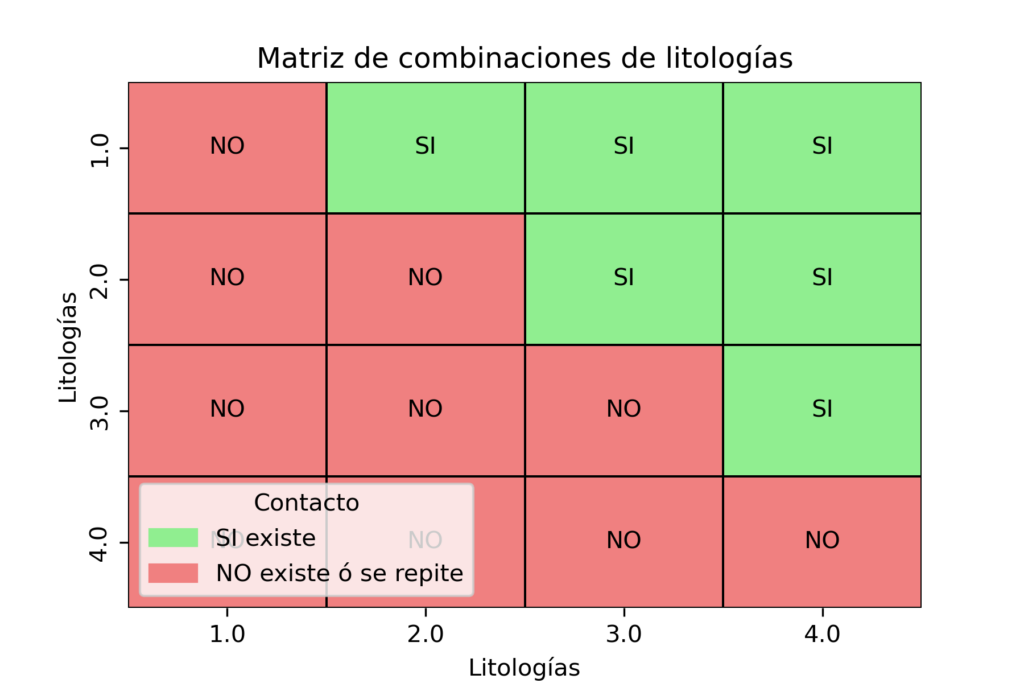
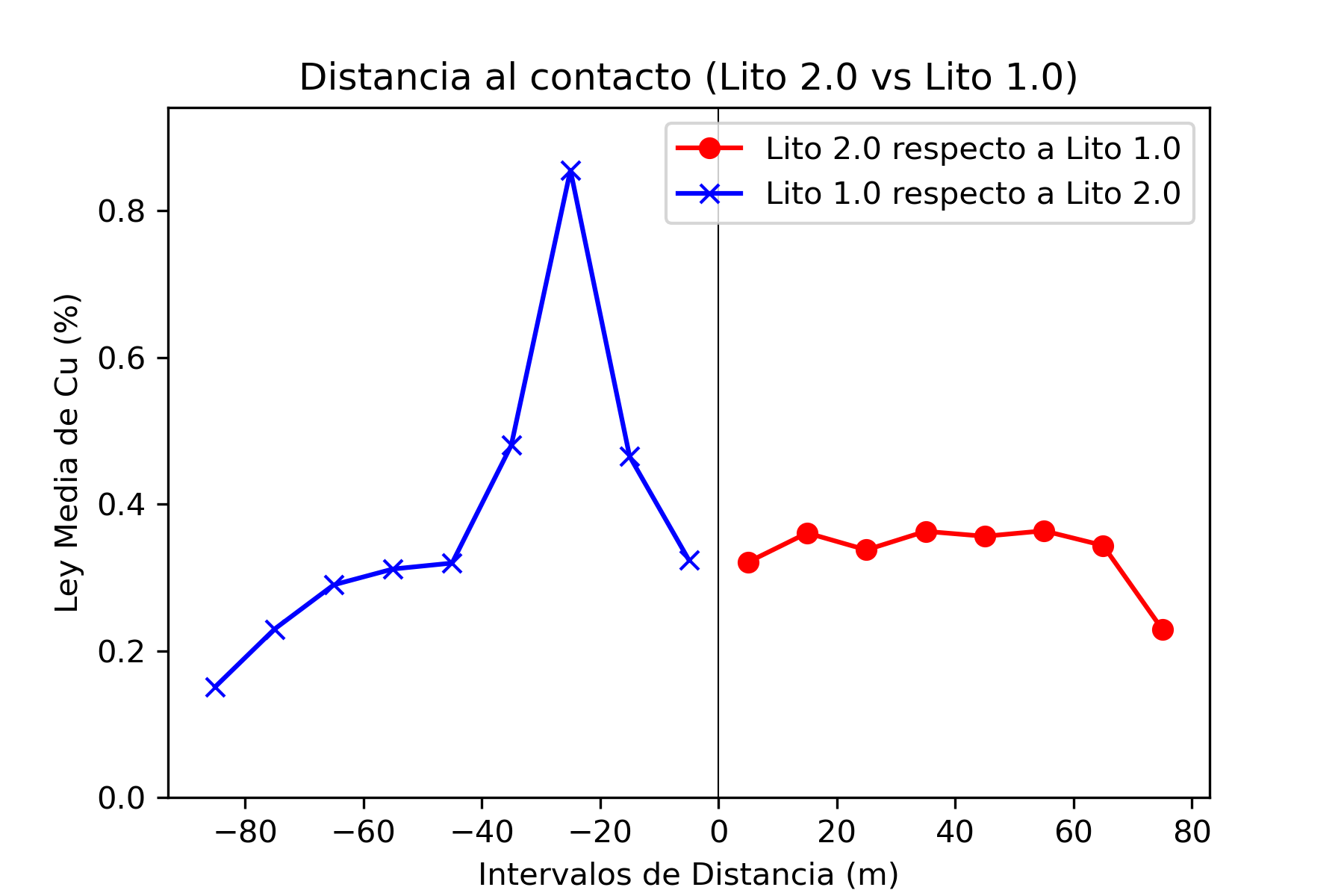
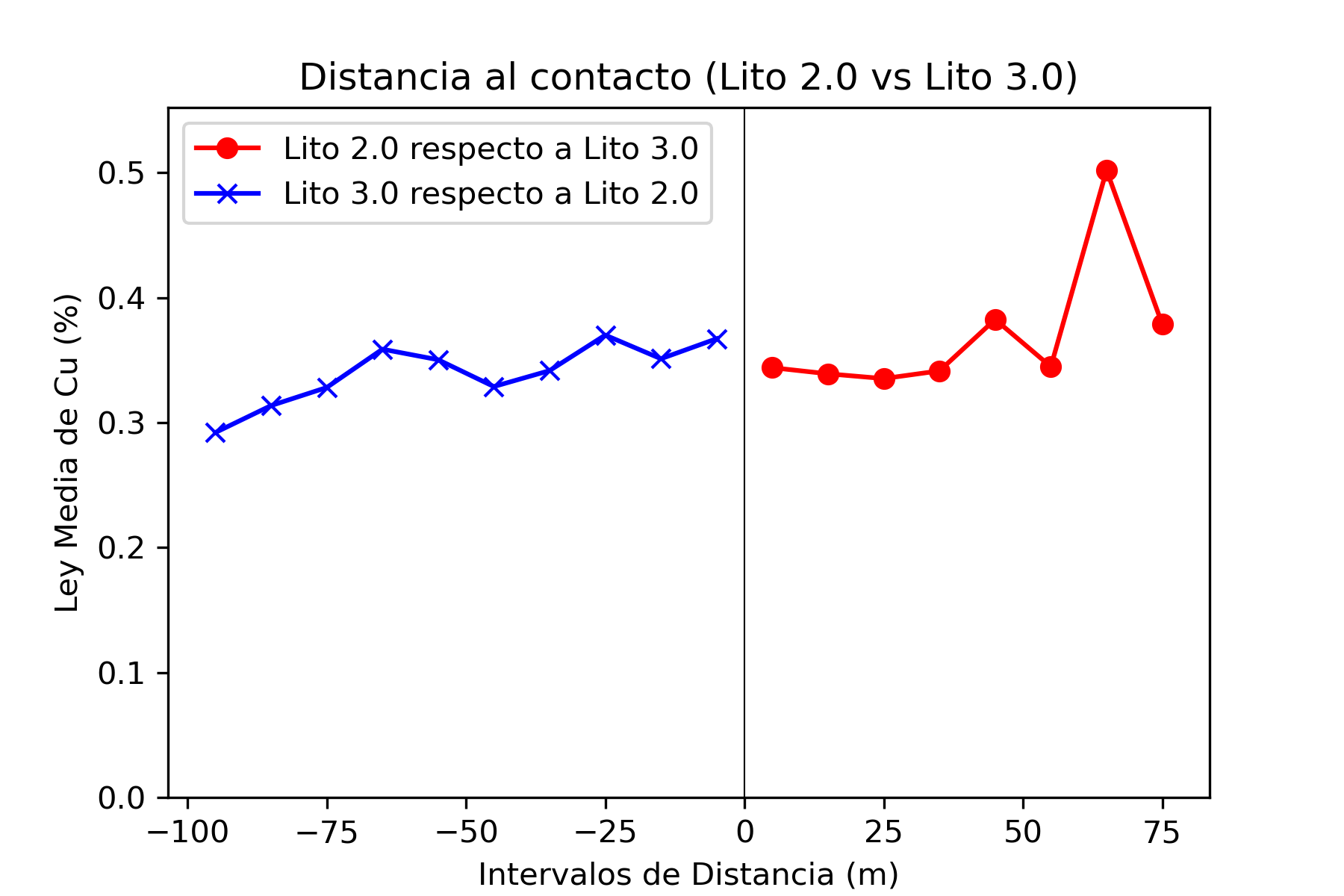
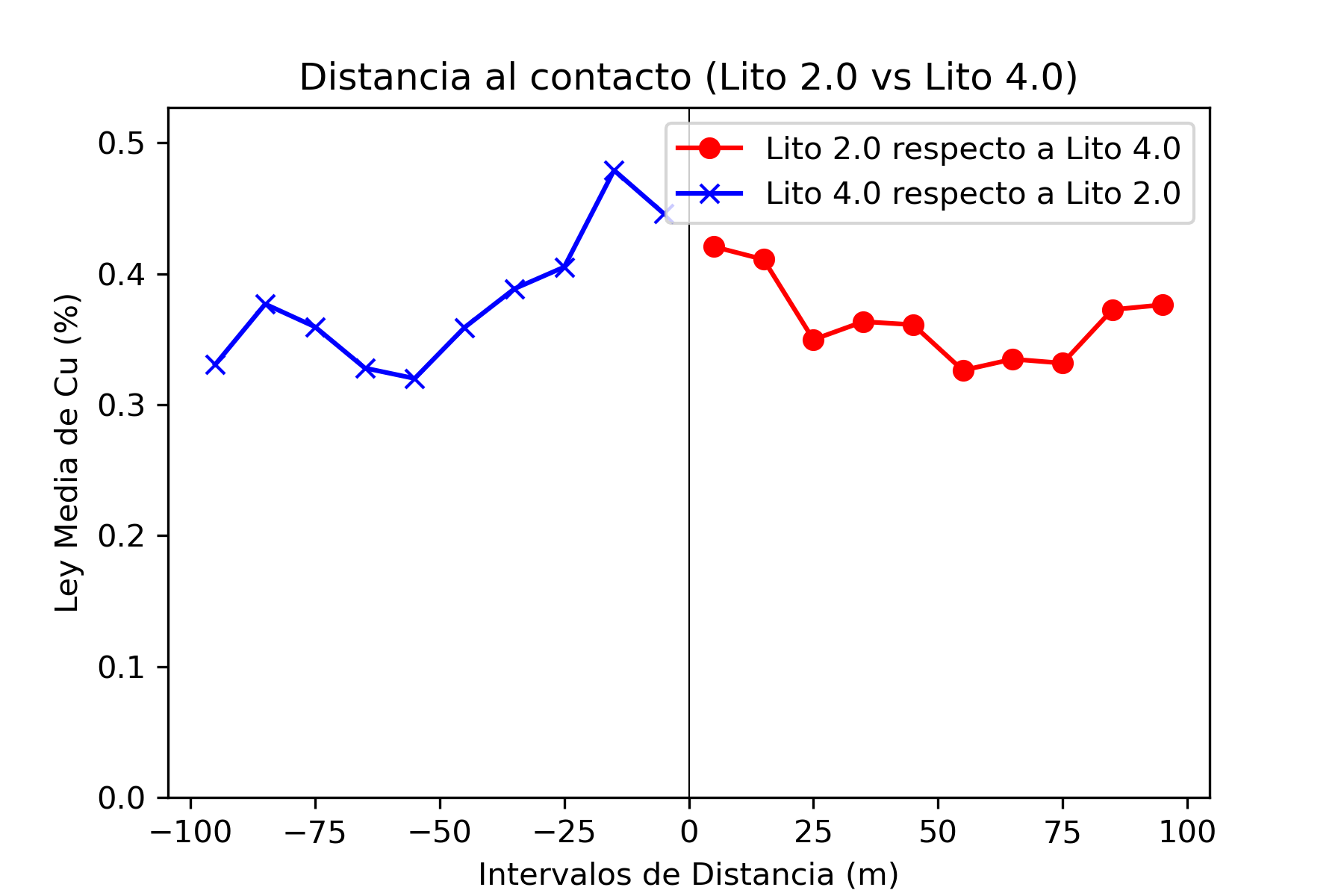
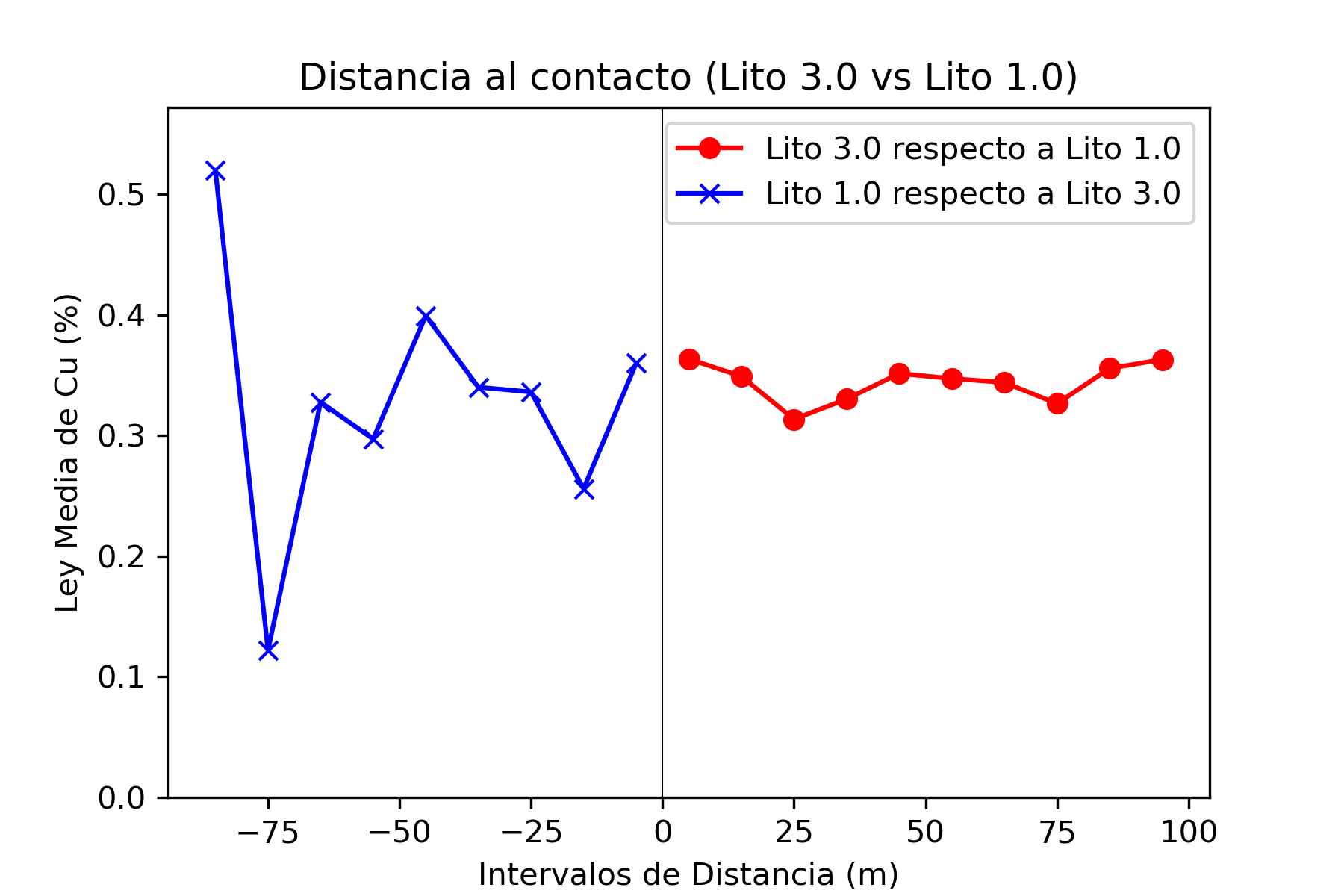
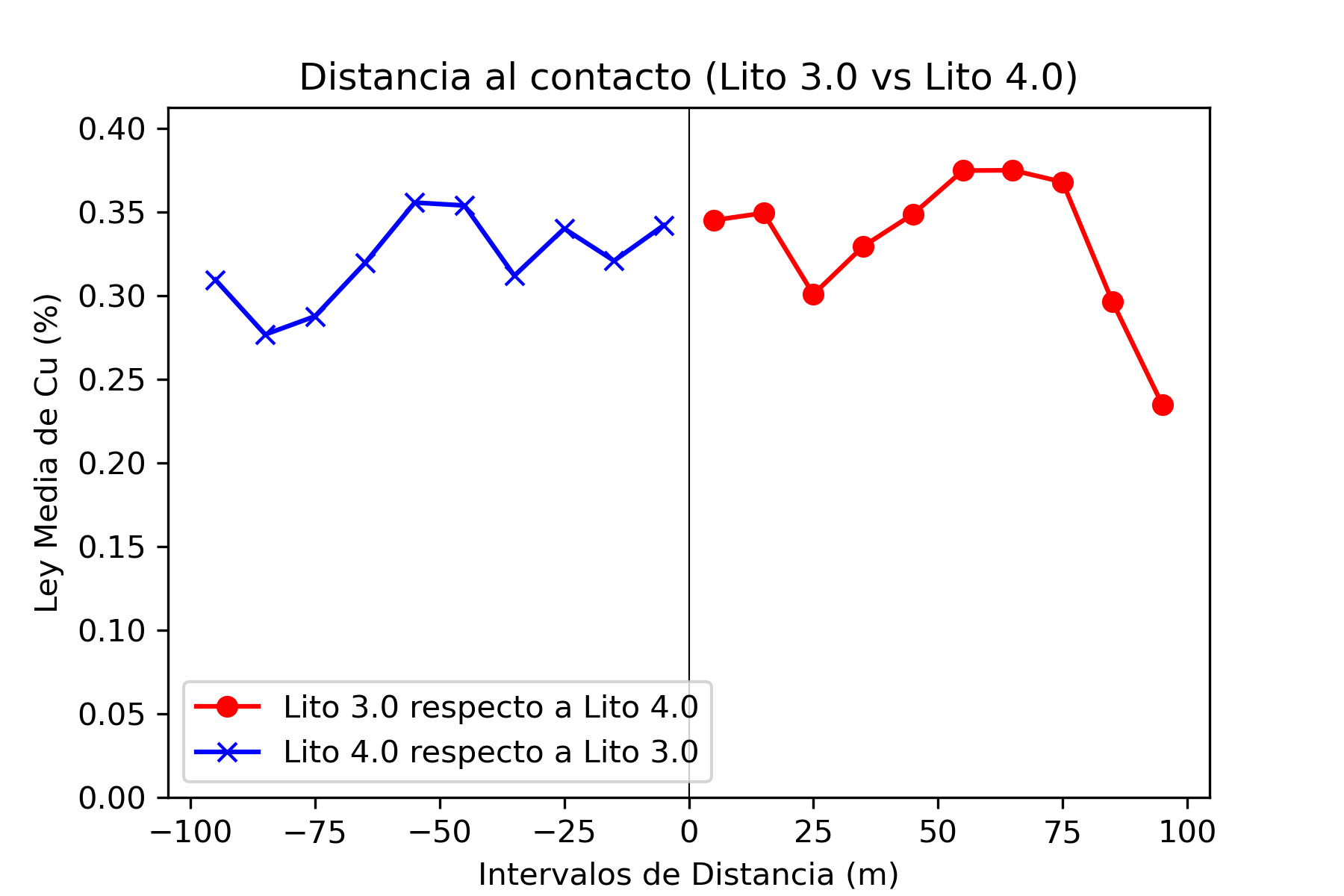
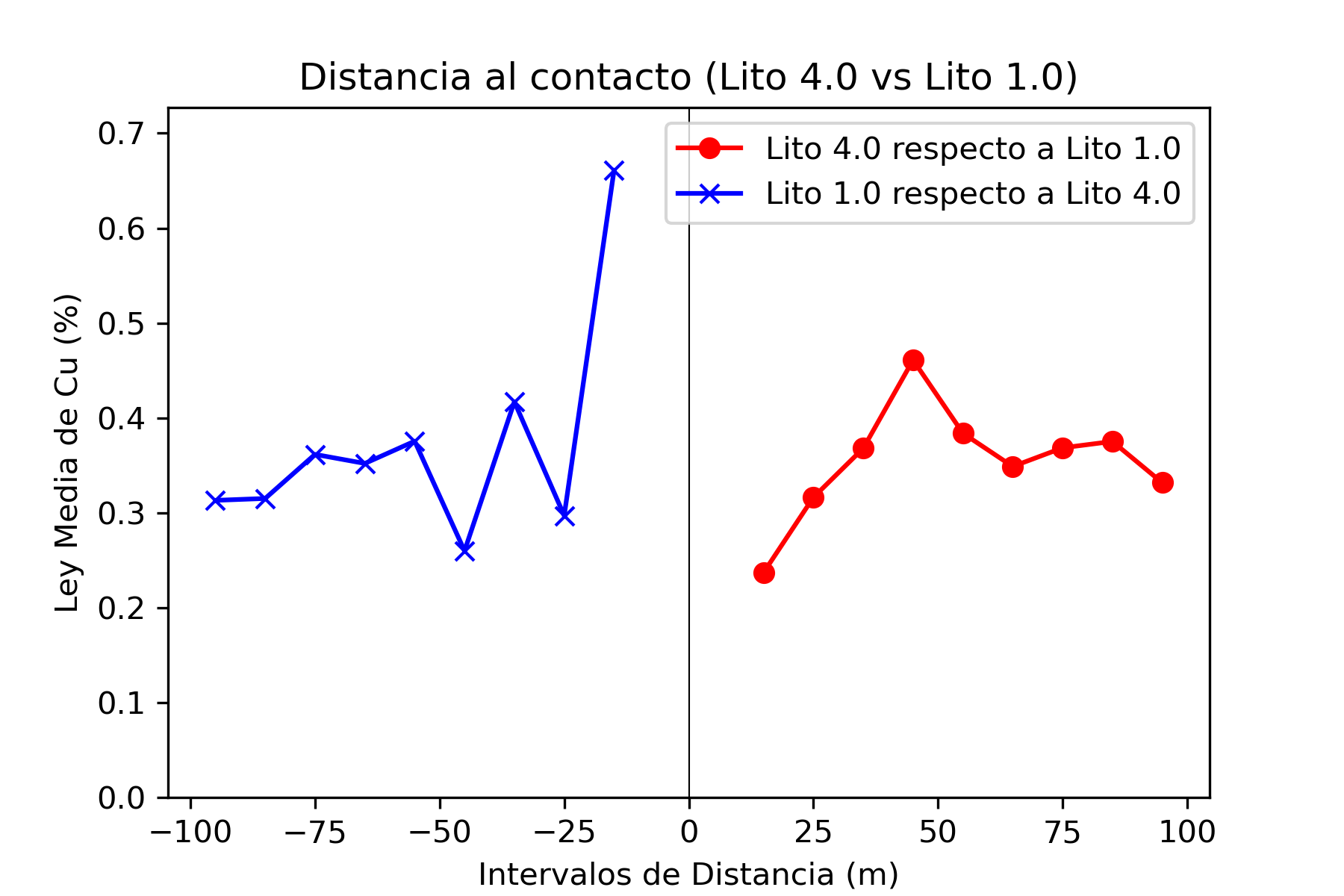
El análisis de contacto es una técnica utilizada en la evaluación de recursos minerales para estudiar cómo cambian las leyes de mineralización (por ejemplo, la concentración de cobre) en las proximidades de los contactos entre diferentes unidades geológicas o litológicas. Este análisis es fundamental para entender cómo se distribuyen los minerales dentro de un depósito y ayuda a definir dominios geológicos y de estimación que reflejen las variaciones naturales en la mineralización.
En este post, comparto un ejemplo y código en Python el cual realiza el análisis de contacto para las leyes de cobre según sus diferentes litologías. El código es extensible a cualquier caso siempre y cuando se mantenga el formato del archivo de entrada.
Sobre el archivo de entrada
Se requiere que el archivo de entrada tenga un ID, coordenadas X, Y, Z, el atributo geológico (por ejemplo litología en este caso), y la ley mineral (cobre en este caso). Puede descargar el archivo «compositos.txt» en el siguiente enlace: