Ley de Corte - Método de Kenneth Lane

LUIS ÁLVAREZ P.
(11 de Septiembre, 2024)
Tabla de contenidos
Sobre el método
El método conocido como K-LANE, es utilizado para determinar la ley de corte óptima en operaciones mineras, ya sea a cielo abierto o subterráneas.
El método considera varios factores, como los costos de extracción, procesamiento, transporte y venta del mineral, así como las leyes minerales y los precios de mercado del producto de interés. La clave del método es su capacidad para optimizar dinámicamente la ley de corte en función de cambios en estos parámetros, permitiendo así una gestión más eficiente y rentable del recurso mineral.
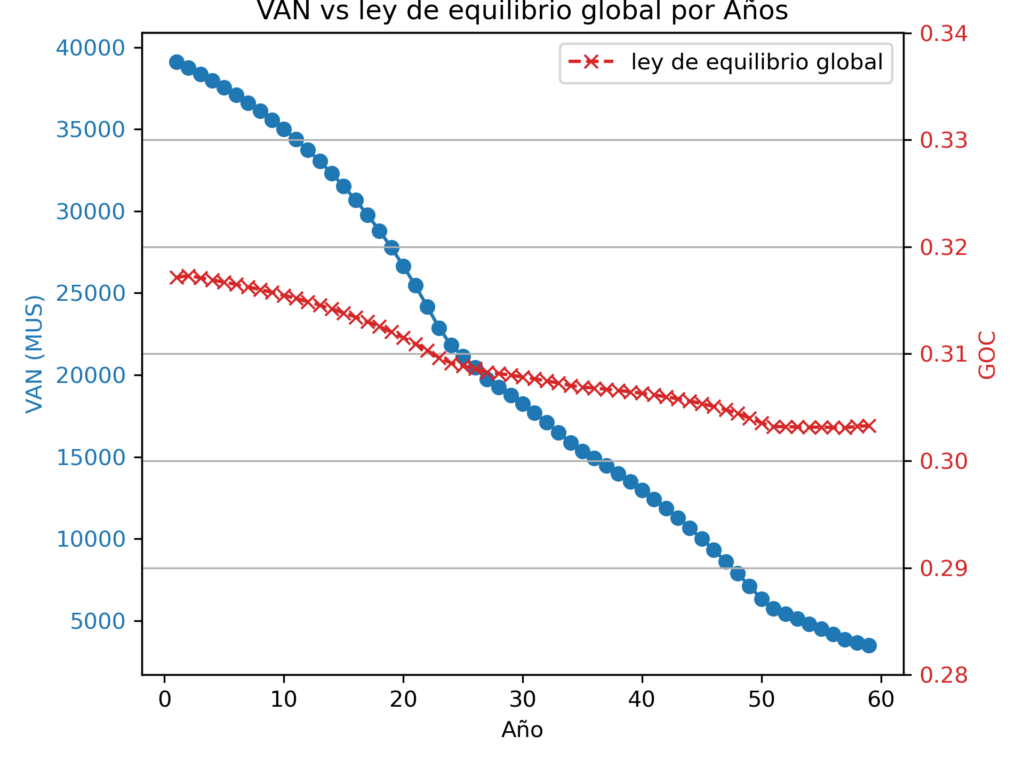
En términos generales, el objetivo es maximizar el valor presente neto (VPN) de la operación minera. Para ello, el método evalúa las diferentes leyes de corte posibles y selecciona aquella que genere el mayor rendimiento económico posible, considerando no solo el valor del mineral recuperado, sino también los costos asociados y las limitaciones operativas de la mina.
El método K-LANE también se adapta a diferentes escenarios y puede incorporar factores adicionales como los impactos ambientales, el uso de tecnologías de preconcentración, y las incertidumbres en los precios de los metales. Por ejemplo, algunos estudios han propuesto modificaciones al método original para incluir costos ambientales o utilizar algoritmos de optimización metaheurística para mejorar aún más la precisión del punto de equilibrio económico.
En resumen, el método es una herramienta robusta y flexible para la optimización de la ley de corte en operaciones mineras, permitiendo una gestión más estratégica y eficiente del recurso, con el objetivo de maximizar el retorno económico de la explotación minera.
Ejemplo implementado en Python
Este es un ejemplo desarrollado paso a paso para la implementación del método de K-LANE. Y por supuesto es reutilizable en cualquier inventario de recursos siempre y cuando este mantenga el mismo formato del de nuestro ejemplo.
Parámetros del método
[snippet slug=k-lane-parte-2 lang=python]
Procedimiento en 12 pasos
[snippet slug=klane-parte3 lang=python]
Resultados