

En esta oportunidad presentamos un simple código preparado con la biblioteca Pandas de Python, que cubica recursos minerales sobre un modelo de bloques (53,271 bloques) denominado Marvin Test Mine (http://mansci-web.uai.cl/minelib/marvin.xhtml). El código es resultado del contenido visto en la primera unidad del curso “Modelado de Datos Espaciales en Python”, en la cual específicamente se trata la importación, manipulación y exportación de tablas de datos.
Todo software minero posee una herramienta para cubicar recursos y reservas. Entiéndase que esta cubicación, no es más que la suma de los tonelajes de un conjunto de bloques que cumplen con las condiciones que se le impongan, por ejemplo, que estén sobre una determinada ley de corte. Esta ultima sería una primera condición, aunque la idea es incluir más de una. En este ejemplo condicionaremos la selección de bloques con tres variables; concentración de cobre, concentración de oro y nivel o cota.
Parte I: Importación del modelo de bloques
import pandas as pd
df = pd.read_excel(‘C:/Users/heber/Desktop/ADEP/unidad_1/importacion/’ + ‘marvin.xlsx’)
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
%matplotlib inline
fig = plt.figure()
ax = fig.add_subplot(111, projection=’3d’)
x = df[‘x’]; y = df[‘y’]; z= df[‘z’]; u= df[‘Au’]
p = ax.scatter3D(x,y,zs=z, c=u, marker=»s», s=10, cmap=’coolwarm’, alpha=1)
ax.view_init(azim=330, elev=30)
ax.set_xlabel(‘Este [X]’)
ax.set_ylabel(‘Norte [Y]’)
ax.set_zlabel(‘Elevación [Z]’)
fig.colorbar(p, ax=ax, label=’Au (ppm)’, pad=0.2)
plt.show()
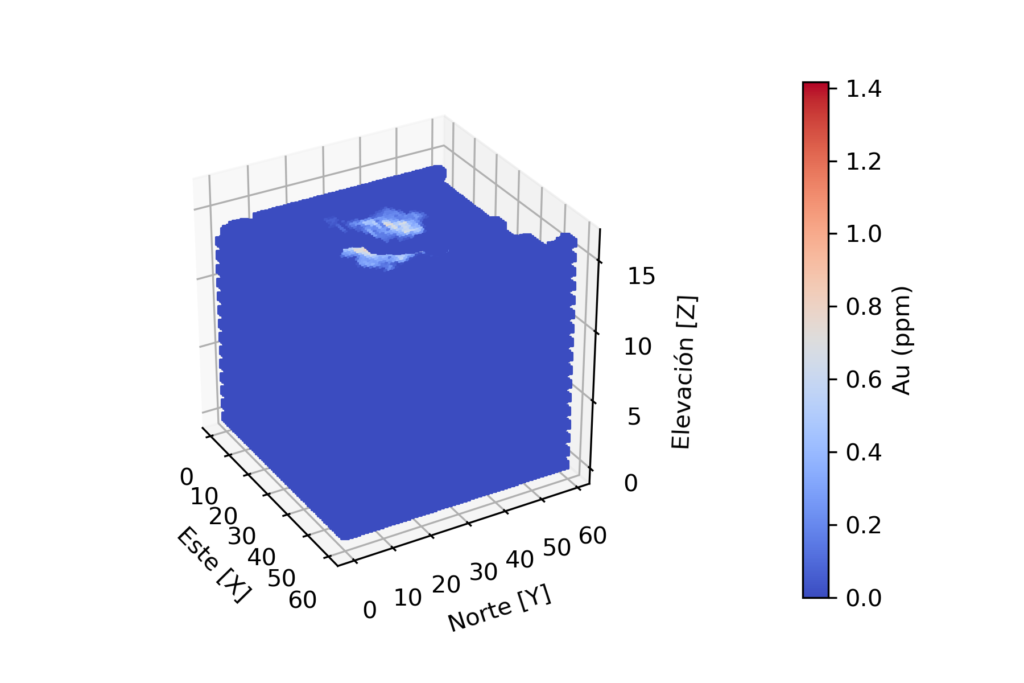
El código en color rojo es únicamente presentado para la visualización del modelo, un adicional en esta presentación para un mejor entendimiento.
Parte II: Manipulación y exportación bloques seleccionados
Au = float(input(‘Ingrese la ley mínima de Au: ‘)); Cu = float(input(‘Ingrese la ley mínima de Cu: ‘)); z = float(input(‘Ingrese el nivel (elevación): ‘))
df_select = pd.DataFrame([(row[‘Au’] >= Au and row[‘Cu’] >= Cu and row[‘z’] == z) ] for index, row in df.iterrows())
df[‘condicion’] = df_select[0]
condicion = df[‘condicion’] ==True
print(‘El N° de bloques que cumple el criterio es de ‘, df.id[condicion].count(), ‘correspondiente a ‘, round((df.id[condicion].count()*100)/df.id.count(),1), ‘% del total, equivalente a’, round(df.ton[condicion].sum()/1000000,1), ‘Mton de recursos minerales.’)
df[condicion].to_csv(‘C:/Users/heber/Desktop/ADEP/unidad_1/importacion/’ + ‘df_select_marvin.csv’)
df[condicion].head()
Lo destacable del código esta en tres lineas (color azul), en donde la instrucción es:
- Consultar a los 53,271 bloques del modelo si cumplen o no con la condición dada (lo cual depende del input que se ingrese).
- Agregar una variable booleana a todos los bloques que es cumple (SI) o no cumple (NO).
- Seleccionar solo aquellos bloques que SI cumplen con la condición e imprimir el numero, porcentaje del total y masa en tonelaje.
En resumen con muy pocas lineas de código, podemos cubicar recursos minerales desde un modelo de bloques. En el vídeo a continuación se ve una corrida del programa.
Sin duda este código puede ser mejorado incorporando mas condiciones, definiendo limites superiores como inferiores en cada variable, visualizando los bloques seleccionados y añadiendo un reporte a nivel estadístico (Unidad II y III del curso “Modelado de Datos Espaciales en Python”).
Debe estar conectado para enviar un comentario.