La compositación es un proceso mediante el cual se ajustan las longitudes de las muestras obtenidas de sondajes para que sean iguales (regularización). Esto implica modificar las longitudes de los ensayos de manera que cada volumen de roca tenga una influencia equitativa en la estimación de la ley mineral de un área específica. La compositación busca facilitar una representación más precisa y equilibrada de las concentraciones de mineral en el yacimiento.
¿Cuál es la importancia de la compositación de sondajes en minería?
La compositación de sondajes es crucial en la minería por varias razones:
Equidad en la Estimación: Asegura que cada volumen de roca contribuya de manera equitativa a la estimación de la ley, evitando que algunas muestras, que pueden ser más abundantes, influyan desproporcionadamente en los resultados finales.
Mejora del Proceso de Exploración: Al estandarizar las longitudes de las muestras, se mejora la capacidad de análisis y se facilita la comparación entre diferentes sondajes, lo que resulta en una mejor toma de decisiones sobre la viabilidad económica de un proyecto.
Reducción de Errores: Minimiza el riesgo de sobrestimar o subestimar la concentración de mineral debido a la variabilidad de las longitudes de las muestras.
El siguiente código composita a 10 metros los sondajes de exploración minera. Esta longitud de compositación es una variable por lo que es una opción del usuario.
Código Python
[snippet slug=compositacion lang=python]
Resultados
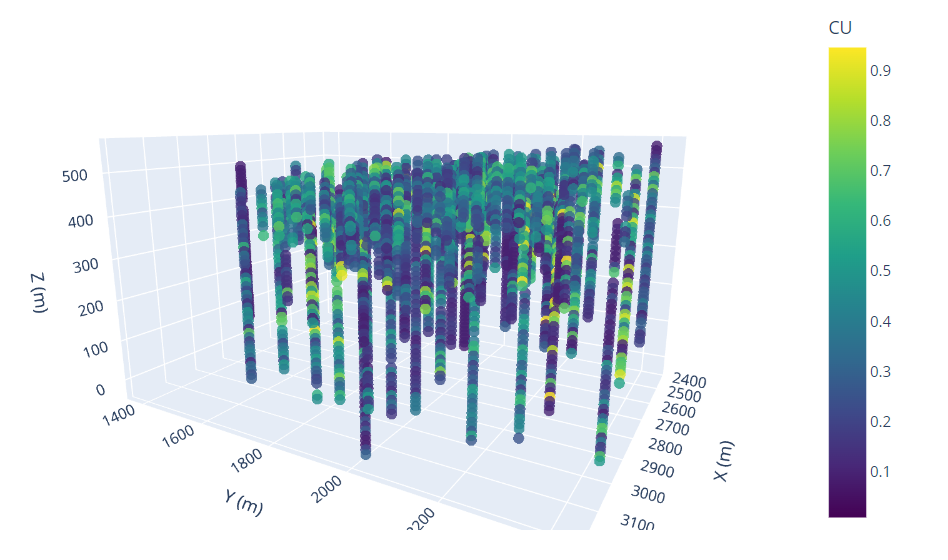
Archivo compositado y referenciado por las coordenadas X,Y,Z en el centro del composito.
Facebook
Twitter
LinkedIn
WhatsApp
Cursos relacionados
Recursos Minerales
12 Cursos
Cursos relativos al uso de geoestadística y otras ciencias aplicadas en la evaluación de recursos minerales.